Better Crash Reporting
Crash events are some of the more serious events that can happen when operating a service. Usually it is crashing components that cause cascading failures and service outages. It is critical to have good visibility into those events, since they can cause major damage and should be avoided.
Unfortunately, debugging crashes is one of the more complicated endeavors. The state of a crashed process is often compromised and the process can’t be trusted to collect debugging information on its own.
In this post we list a few desirable properties that we want crash reporting to have in order to enable and simplify effective debugging. Afterwards we are going to report on some progress we have made towards these goals, with our Circonus internal components.
Crash Reporting Wishlist
In case of a crash, some key questions to answer are:
-
In what state was the process at the time of the crash event?
-
What are the events that lead to this error?
Of course, we could answer those questions by taking a full core-dump together with an archive of the log directory and call it a day. The only downside is that your crash-handler will take hours to run and leave the operator with the overwhelming task to make sense of gigabytes of unstructured data.
The core balance to strike when implementing effective crash reporting is between the breadth of information to capture and the size of the crash report. We have to be selective with the information we capture to allow the crash handler to finish its work within seconds. The crash-report should be no-larger than a few megabytes and presented it in a way that is useful to operators.
A good crash report should contain the following bits of information:
Meta Information
-
Meta information like time, host, service, etc. (“tags”).
-
Meta information about the exact version of the loaded executables and libraries.
State Information
-
Stack traces of all active threads/coroutines in the process.
When using event loops: The list of pending events on each queue. -
The values of all local variables on active stack-frames.
When those variables are pointing to structs/objects we want to have the stored attribute values of those objects as well - up to a sensible recursion depth. -
The list of all active work units (requests/transactions/spans) that the process was executing at the time of the request.
Context Information
-
Recent memory, CPU, disk and network utilization.
-
A list of recent completed units of work, e.g. output of
tail accesslog.
Common Pitfall: Logging
There is a common pitfall, when trying to extract crash information from logs or event data: Logs are only written once the request is completed. Otherwise you won’t have information about http return code, payload length or request duration.
So, if you crash during a request is being serviced, you will not have log line/event for this very request. A public example, of this exact problem can be found here:
None of [our] traces showed this because the traces in flight were destroyed by the OOM and never transmitted to metamonitoring. The black box monitor of AWS ALB logs did tell us we had a problem, but we misinterpreted the signs.
It’s for this reason that whish “#4 - List of active work units” is non-trivial to attain.
In-Process vs. Out-of-Process crash handling
In-Process crash handling is like trying to rescue paper-work from a burning building. Out-of-Process crash handling is the forensic work that you carry out on a closed-off crime-scene the next day.
In some crash situations the application is able to execute an exception handler before going down. This is the case for usual exception handling, as well as for signals like SIGABRT, SIGSEGV, SIGTERM that can be hooked with a signal handler. The application can then try to collect some debugging information on its own behalf. But there are some difficulties that make that task hard:
-
Signal handlers may be called at any point in time, so the process state might be temporary inconsistent. We might be in the middle of a update operation or a memory allocation.
-
Signal handlers must be re-entrant. It’s possible for a signal handler to be called while executing a signal handler.
-
The process state might be corrupted as a result buffer overflow or use-after-free issue. Memory corruptions bugs may mean that the callstack is unsalvageable. Some threads might even be non-reachable when critical thread meta-data is sufficiently corrupted.
If your in-process crash handler can’t cope with any of those difficulties you might corrupt the process state even more, or risk hanging or crashing inside the crash handing routine. At the very least you will have incomplete information to work with.
Out-of-process crash handling looks at a stopped process or a core-dump and treats it as a gigantic byte array, together with a few bytes of register state. From there, it tries to figure out what was going on by poking at the memory contents.
The good thing about this approach is that it is much more reliable and safer. You can’t corrupt the state any further. You are not running inside the constrained environment of a signal handler. This means you can perform more complex analysis tasks, like detection of heap corruptions or stale pointers. Also, you have additional flexibility as an operator, since you need the application itself to come with the right crash handling code.
The downside, of course, is that you have to understand the exact memory contents of your application. This quite doable with low-level languages like C, but get’s much harder with interpreted languages like JavaScript, Python or Lua. For an example on how this might look like see Cantrill,Pacheco - Dynamic Languages in Production (GoTo 2012), which talks about the same problem in the context of dynamic tracing of Node.js.
Crash Reporting at Circonus
In the last months we took a few step towards our goal of better crash reporting in our open-source application framework libmtev which underpins most of the Circonus components.
Watchdog supervision
The first piece in the puzzle is the mtev watchdog process. Mtev applications run under the supervision of a parent process called “watchdog”, that coordinates in-process and out-of-process crash handling.
To do so, the child process registers signal handlers for common crash signals. From the signal
handler (emancipate) stop’s itself (using SIGSTOP), which in-turn notifies the watchdog process
to trigger out-of-process crash reporting routines. Afterwards the child process is continued and
free to perform in-process crash handling and cleanup work (write logs, capture stack traces) by
itself.
Here is a simplified interaction diagram from src:
/-----------------/ /-----------------------/
/ Child running / / parent (watchdog) /
/-----------------/ / waiting /
| /-----------------------/
| |
(crash SIGSEGV/SIGABRT/SIGILL/...) |
| |
/--------------------------------------------------/ |
/ `emancipate` / |
/ Child annotates shared memory CRASHED indicator / ---(notices crash: SIGCLD)
/ Child SIGSTOPs itself. / |
/--------------------------------------------------/ |
| |
| /-------------------------------------------/
| / Parent runs out-of-process crash handler /
|<----(wakeup: SIGCONT) ------------------------/ Send SIGCONT to child. /
| /-------------------------------------------/
| |
/-------------------/ |
/ Log stack trace / |
/ notify parent /-------(notify parent via shread-mem)-->|
/-------------------/ |
| /-------------------------/
/-------------------------------------/ / spawn new child process /
/ Child runs in-process crash handler / /-------------------------/
/ Child reraises signal /
/-------------------------------------/
|
(terminated)
Crash artifacts (core-dumps, crash-reports, logs) are written to dedicated directories on the file system, from where there are picked-up by separate processes that upload them to centralized places, and trigger Slack or e-mail notifications.
Plain stack traces
Stack traces are the most common artifact that is salvaged from a crash. It’s possible to generate stack traces from inside inside the process (via backtrace(3)/libunwind), but it can also be extracted from a stopped process or a coredump (via gdb(1)/pstack(1)).
Here is an example of an in-process stack trace:
[ 00 ] ld-2.17.so _dl_fixup
[ 01 ] ld-2.17.so _dl_runtime_resolve_xsave
[ 02 ] libunwind.so.8.0.1 _ULx86_64_init
[ 03 ] libunwind.so.8.0.1 unw_init_local_common
[ 04 ] libunwind.so.8.0.1 _ULx86_64_init_local
[ 05 ] libmtev.so.1.10.4 mtev_backtrace_ucontext ( mtev_stacktrace.c:956 )
[ 06 ] libmtev.so.1.10.4 mtev_stacktrace_ucontext_skip ( mtev_stacktrace.c:994 )
[ 07 ] libmtev.so.1.10.4 emancipate ( mtev_watchdog.c:627 )
[ 08 ] libpthread-2.17.so
[ 09 ] libc-2.17.so __GI_raise
[ 10 ] libc-2.17.so __GI_abort
[ 11 ] libluajit-5.1.so.2.1.0 lj_vm_ffi_call ( lj_clib.c:38 )
[ 12 ] libluajit-5.1.so.2.1.0 lj_ccall_func ( lj_ccall.c:1161 )
[ 13 ] libluajit-5.1.so.2.1.0 lj_cf_ffi_meta___call ( lib_ffi.c:230 )
[ 14 ] libluajit-5.1.so.2.1.0 lj_BC_FUNCC ( lj_clib.c:38 )
[ 15 ] lua_mtev.so mtev_lua_resume ( lua.c:296 )
...
[ 24 ] libmtev.so.1.10.4 eventer_epoll_impl_trigger ( eventer_epoll_impl.c:375 )
[ 25 ] libmtev.so.1.10.4 eventer_epoll_impl_loop ( eventer_epoll_impl.c:536 )
[ 26 ] libmtev.so.1.10.4 thrloopwrap ( eventer_impl.c:716 )
[ 27 ] libpthread-2.17.so start_thread
There are a few things to note:
-
We see the signal handler
emancipatefrom mtev_watchdog.c on the stack. At this place the application is interrupted by the signal handler, and a stack trace is taken. -
We see a few frames from
libluajit_*in the stack trace, which indicates that we have been running some Lua code during the crash. Unfortunately, we don’t know much about what we where doing inside of Lua.
We will see how to improve on both of these aspects below.
Full stack traces with backtrace.io
We use the ptrace tool provided by backtrace.io for out-of-process crash reporting. The stack traces extracted by this tool include the values of local variables (fully symbolized), thereby realizing #2 and #3 from our list for parts of the system written in C. backtrace.io reports can be presented in a web console, which looks like this:
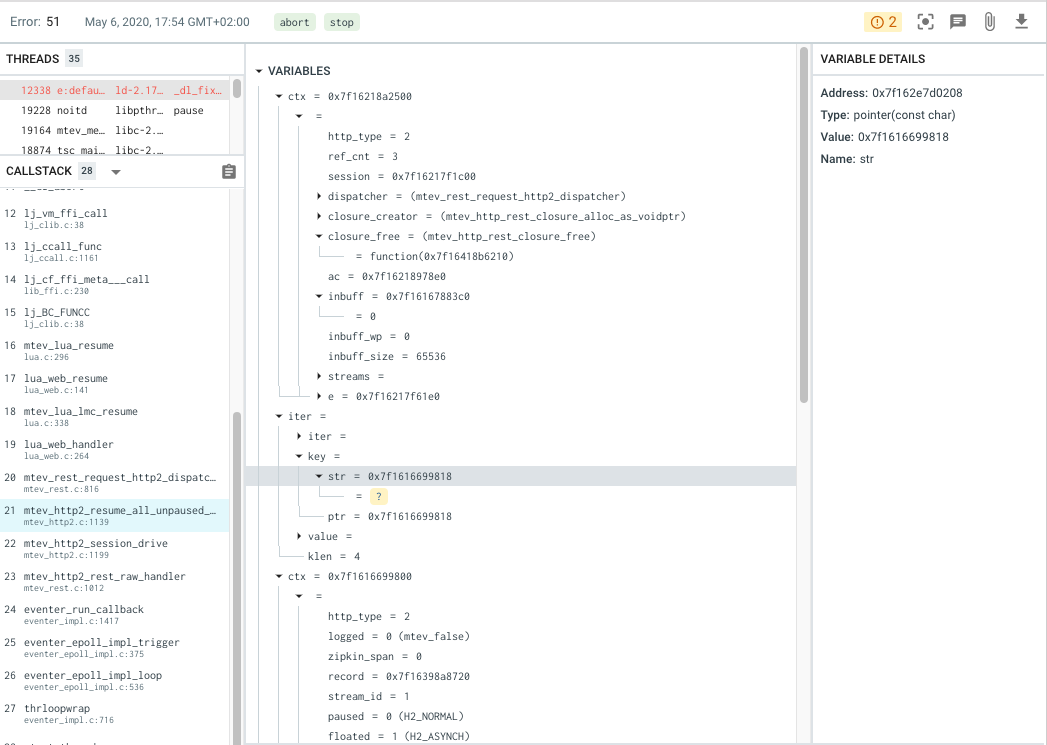
These reports can further be annotated with meta information about the environment and versions in the form of key-value tags, which allows us to realize goals #0 and #1.
Mixed-mode stack traces
When running interpreted languages like Lua, the C stack traces shown above will not be very helpful. The only information they provide is essentially: “You have been running Lua code” – Well, thanks very much. In cases like this, you ideally want mixed-mode stack traces, that interleave the Lua stack frames with the C stack frames of the interpreter.
batcktrace.io provides mixed-mode stack traces out of the box for a number of run-times including Python, Java, Node.js. Unfortunately for us, Lua/LuaJIT is not directly supported at the time of this writing.
To work around this, and get mixed-mode stack traces from production crashes, we resort to
in-process crash handling, and call lua_getstack from the signal handler
(src)
and hope for the best: 🤞. When it works, it looks like this:
STACKTRACE(23835):
> /lib64/libc.so.6'gsignal+0x37[0x36387]
> /lib64/libc.so.6'abort+0x148[0x37a78]
> /opt/circonus/lib/libluajit-5.1.so.2'lj_vm_ffi_call+0x84[0xccb6]
> -- mtev lua runtime stacktrace --
> stack traceback:
> [C]: in function 'abort'
> [string "return function(http)..."]:16: in function <[string "return function(http)..."]:14>
> [C]: in function 'xpcall'
> /opt/noit/prod/share/lua/support/rest_utils.lua:74: in function 'handle_request'
> [string "return function(http)..."]:19: in function 'f'
> /opt/noit/prod/libexec/noit/lua/web.lua:87: in function 'serve'
> /opt/noit/prod/libexec/noit/lua/web.lua:124: in function 'serve'
> /opt/noit/prod/libexec/noit/lua/web.lua:155: in function <web.lua:127>
> /opt/circonus/lib/libluajit-5.1.so.2'lj_ccall_func+0x35b[0x4df8b]
> /opt/circonus/lib/libluajit-5.1.so.2'lj_cf_ffi_meta___call+0x37[0x62527]
> /opt/circonus/lib/libluajit-5.1.so.2'lj_BC_FUNCC+0x1c85[0xa895]
> /opt/circonus/libexec/mtev/lua_mtev.so'mtev_lua_resume+0x16e[0x812e]
...
> /opt/circonus/lib/libmtev.so.1'0x9ae79
> /lib64/libpthread.so.0'start_thread+0xc5[0x7ea5]
> /lib64/libc.so.6'clone+0x34[0xfe8dd]
When it does not work, we usually get a SIGSEGV from the crash handler.
So far this has been working OK for us, and provides valuable insight in 80% of our Lua-related crashes. In the mid-term future we would like to move to a more reliable solution, involving out-of-process tracing. One way to do this, would be to extend the backtrace.io-tracer with an appropriate module (see below). We might invest some time into this in the future.
Salvaging Active HTTP Requests
The most interesting unit of work in most of our applications are HTTP requests. With old-school thread-based concurrency model, information about HTTP requests were readily extracted from active stack traces. In the event-based systems, like ours, active HTTP requests don’t always manifest themselves in stack frames. A request might dispatch into dozens of micro-tasks that are executed in different even loops or job queues, waiting to be re-assembled upon completion. This makes reconstructing active HTTP requests from local variable state impractical.
There are two approaches to salvaging active HTTP requests from a crashed mtev app:
-
Leveraging the DistributedTracing/zipkin module
-
Leveraging the http_observer module
Leveraging DistributedTracing data (1) is fundamentally more powerful approach since it is not tied to HTTP requests and applies more generally to application instrumented with tracing technology (cf. OpenTracing). Libmtev comes with a Zipkin module, that annotates HTTP requests with spans, which could be leveraged for the task at hand. There are open practical questions about sampling and global book-keeping that led us to punt on this approach for now.
For the case of HTTP requests, libmtev already comes with a global register of active and recent requests as part of the http_observer module (2), which allows the operator to view them from within the admin web console:
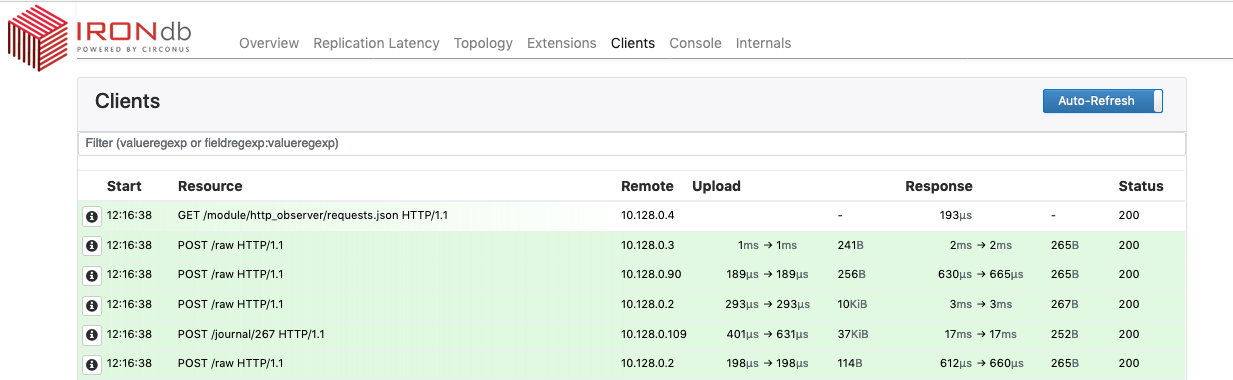
The list of active HTTP requests can be extracted by an out-of-process tracer by inspecting a global (static) hash table. We have built a backtrace.io tracer module that walks this hash table using a provided raw-memory API, and attaches a list of active HTTP requests to the crash report:

This allows us to get a precise high-level picture about the current work-load that the component was serving at the time of the crash.
Conclusion
When done right, crash-reporting can speed up the debugging process for production incidents dramatically and lead to a more methodical approach to isolating root-causes.
It allows you to be less of a fire fighter and more of a police detective.
In this article we outlined a vision on how we would like effective crash reporting tooling to look and explained some of the steps we have taken in this direction.
By leveraging tooling provided by backtrace.io we were able to a lot closer to our visibility goals for crash events and hangs. We have been able to narrow the gap further, by writing our own backtrace.io-modules. With this, we are now able to get
-
Full stack traces with local variable state for all C-based components
-
Mixed-mode stack traces for Lua/LuaJIT-related crashes
-
Concise information about active HTTP requests at the time of the crash
All this is delivered in the form of crash reports to a Slack channel ready for immediate inspection via a powerful web UI. This saves us many hours of debugging and email support every month. In some cases we were able to root cause problems right from the crash report, and ship a fix only a few minutes after the crash first occurred.
However, we think that crash reporting could be even better. Areas where we would like to improve our visibility include:
-
Integrating with distributed-tracing tools to annotate crash reports with high-level information about active work units/spans at the time of the crash.
-
Integrating with monitoring tools to provide better contextual information about resource usage and historic behavior of the application.
-
Improve the visibility into interpreter state for Lua/LuaJIT. In particular regarding stack traces and variable state. This seems to be already working well for more main-stream languages like Python or Node.js.
We are looking forward to future development in these areas.