Distributed Scraper Design
We are am confronted with the following situation:
- A scraper process is downloading files from a remote location. The files are 1-10MB in size, and there are many of them (~500K).
- Each file shall pre processed by a worker process, which extracts some information (about 1K each) and passes them on to a collector process, which does further processing.
We search an architecture meeting the following requirements:
- Allow multiple workers. The worker task is CPU intensive and I want to be able to exhaust all CPU cores or multiple machines on a cluster.
- Allow multiple scrapers. Further files may be downloaded from different sources or on different machines.
- We want to keep a copy of the donwloaded blops at a centralized location. At a later time we might decide to re-ingest all the files at once.
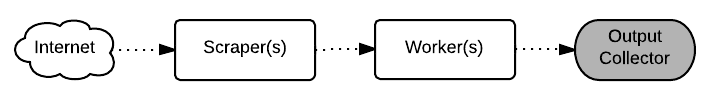
We will use the zmq messaging library [1] for message passing and queing.
Draft 1: All in one
Scraper and Worker are executed in one process, and comunicate directly with the collector process.
- Processes
- ScraperWorkers: Download blop and perform work on it. Dynamic component that can have several instances.
- Collector: Receives processed data. Static component, that exists only once.
- Channels
[ScraperWorker|PUSH] -> [PULL|Output Collector]- output as string messages (line by line).
Discussion
- Pros:
- Simple architecture
- few static pieces (only the Collector)
- Cons
- Parallelism of worker threads coupled to download scripts.
- Monolytic architecture violates principle of separation of concerns [2]
- Central storage of the downloaded files has to be added.
The architecture is clearly not optimal, although it might get you a long way. There can be many ScraperWorkers, that give room for parallelism. In my application the download is the bottleneck, so that there is not too much time wasted by waiting for the worker to finish. The network can be easily kept saturated with a few more ScraperWorker tasks.
There is a architecture principle, that is violated here, of spreading out the work in as may intermediate steps as possible. In this way testing and monitoring becomes easy. Process steps can be reused, and paralellism can be added preciesly where the current bottlenecks are. When the implementation is matured several steps of the architecture might be squashed to a single step.
Draft 2: Pass everything
Pass the donwloaded blops as messages to the worker. Add a proxy to allow dynamic allocation of workers and scrapers.

- Processes
- Scrapers. Dynamic component.
- Proxy. Static component. Collects downloaded files, passes them to workers.
- Workers. Dynamic component.
- Collector.
- Channels
[Scraper|PUSH] -> [PULL|Proxy]- pass downlaoded blop as binary message.[Proxy|PUSH] -> [PULL|Worker]- pass downlaoded blop as binary message.[Worker|PUSH] -> [PULL|Collector]- output as string messages.
Discussion
- Pros:
- Simple design
- Separation of Concerns
- Cons:
- Downloaded blops are transfered through network twice.
- Changing the architecture by adding routing is expensive.
- Central storage of the downloaded files has to be added.
- Reingest of the data requires re-download of files
Draft 3: Central storage
Scraper store downloaded blops on a centralized storage node. The central storage could be a file system location or a database. The passed messages contain only paths to files on the storage node.
The storage node could be mounted at the boxes running the scrapers and the workers, so that the details of the storage solutions are abstracted from the components.

- Pros:
- Small message size. Easy routing. Little overhead for proxy.
- Centralized storage built in.
- Cons:
- Storage node is bottleneck and single point of failiure
Draft 3b: Distributed storage
Scraper store downloaded blops to a distributed file system. The files will be cut into containers and distributed around all available storage nodes. The storage nodes can be different from the nodes running the scrapers/workers but do not have to be.

- Pros:
- Relieable storage with high write throughput.
- Cons:
- Additional network overhead for synchronization of files.
There is additional juice in this option as it allows to bring the computation to the storage. It should be possible to run the worker tasks processing the downloaded files on the node that runs the scraper. This would allow the scraper box to use its computing power for something sensible while waiting for the network.
Since HDFS [3] can be mounted to a folder, this solution can be interchanged with draft 3.
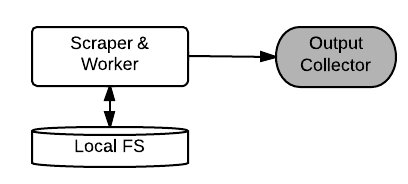
Draft 4: Scraper storage
Scrapers store downloaded blops locally. The network locations ($HOST:$PATH) of the downloaded files are passed as messages. The worker thread reads the contents of the file directly from the scraper’s file system (e.g. via ssh)

- Pros:
- Minimizes network overhead. No file transfer unless absolutely necessary.
- Cons:
- Makes scrapers inflexible. Need to be up and running while processing.
- Bottleneck: scraper storage.
Final Discussion
Currently I like the Draft 3 option best, since it is reasonably simple, while allowing parallelism and compying to the separation of concerns principle. It allows to resume work when the service is stopped or crashes rather easily, since the downloaded files are available on a central location. When the storage becomes a problem it is possible to upgrade to Draft 3b, which uses a distributed file system.
References
- http://zeromq.org
- http://en.wikipedia.org/wiki/Separation_of_concerns
- http://en.wikipedia.org/wiki/Apache_Hadoop#Hadoop_distributed_file_system